
오늘 네이버 공식블로그에 올라온 공지인데요
지난 11월 1일 쯔음부터 변경된 웹사이트 네이버 노출 순위 변경과 관련
아래와 같이 네이버 공식블로그에 설명을 해주셨는데..
솔직히 "뭔가 바꾸는 작업을 하긴 했구나?" 외에는
기술적인 내용은 전혀 이해가 안되네요.
일단, 다른분들도 참고하시라고 링크 겁니다.
원문 링크 url : https://blog.naver.com/naver_search/221706818163
아래 내용(복사함)
네이버 웹사이트 검색 영역에 나열되는 검색 결과의 순서는 랭킹 모델에 의해 결정됩니다. 랭킹 모델이란 사용자가 입력한 질의에 대해 웹페이지 검색 결과를 노출하는 순위를 정하는 알고리즘인데요, 이 알고리즘은 학습 데이터 Training Data 를 통해 자동으로 만들어집니다. 지난 10월 31일 적용된 새로운 웹사이트 검색 랭킹 모델에 적용된 방법을 소개합니다.
학습 데이터란 무엇인가요?
사람이 학습을 통해 더 똑딱해지 듯, AI 모델도 학습을 통해 더 똑똑해집니다. AI를 학습시키기 위해 사용하는 데이터를 학습 데이터라 합니다. 일반적인 지도 학습 Supervised Learning 환경에서 똑똑한 AI 모델을 만들기 위해서는 대량의 학습 데이터가 필요하기 때문에 데이터 확보는 AI 모델 개발 과정에서 가장 핵심적인 일 중 하나입니다. 예를 들어 개와 고양이의 사진을 구분하는 AI 모델이라면 개와 고양이가 태깅 Tagging 된 많은 수의 사진이 필요합니다. 이와 같은 이유로 최근에는 AI용 학습 데이터 구축을 전문적으로 하는 업체들도 여럿 등장했습니다.
검색을 위한 학습 데이터는 어떤 형태인가요?
일반적으로 검색 결과는 사용자 질의와 웹페이지 사이의 적합도 Relevance 순으로 나열됩니다. 따라서 랭킹 모델의 목적은 사람이 하듯이 사용자 질의와 웹페이지를 보고 적합도를 계산해내는 것입니다. 랭킹 모델이 이 일을 배울 수 있도록 검색을 위한 학습데이터는 <질의 – 문서 – 적합도> 형태로 구성됩니다. 예를 들어 ‘네이버’란 질의에 대해 ‘https://www.naver.com/’란 문서의 적합도는 5점이라고 태깅되어 있습니다.
사람이 질의와 웹페이지에 대해 적합도 점수를 부여하는 기준은 네이버 웹사이트 검색 품질 가이드라인에 정의돼 있고, 이 가이드라인에 따라 학습데이터 태깅 전문 인력이 학습데이터를 구축합니다. (자세한 품질 평가 가이드라인은 추후 공개 예정입니다)
적합도 점수 | 대상 문서 |
5점 (완전히 적합) | 사용자가 질의를 넣었을 때 이동하고자 하는 웹사이트. 혹은 사용자 질의에 대한 공식적인 정보를 제공하는 문서. (모든 질의에 5점짜리 문서가 있는 것은 아님) |
4점 (매우 적합) | 사용자 질의와 관련된 정보를 충분히 제공하는 문서로 사용자의 검색 의도를 충족시킬 수 있는 문서. 혹은 질의에 해당되는 공식 정보를 제공하는 소셜미디어 채널들 |
3점 (적합) | 사용자 검색 의도를 전부, 혹은 일부 만족하는 적당한 품질의 문서 |
2점 (조금 적합) | 문서에 사용자 질의가 포함돼 있지만 사용자의 검색 의도를 만족시키지 못하는 문서. 문서의 내용과 품질이 부실 |
1점 (부적합) | 사용자 질의와 무관한 문서 |
검색을 위한 학습 데이터 태깅은 다른 AI 분야의 학습 데이터를 만드는 일보다 훨씬 더 어려운 작업이라 검색을 위한 데이터 구축에는 다른 분야의 학습 데이터를 구축하는 데 비해 시간과 비용이 더 많이 소모됩니다.
준지도 학습과 새로운 웹사이트 검색 랭킹 모델
최근에는 만드는 데 비용이 많이 소모되는 태깅 된 데이터 Labelled Data 를 보완하기 위해 대량의 태깅 되지 않은 데이터 Unlabelled Data 와 사용자 반응 User Feedback 같은 정보를 모델 학습에 활용하는 연구들이 많이 발표되고 있습니다. 이러한 준지도 학습 방법 Semi-supervised Learning 은 상황에 따라 오히려 잘못된 예제를 학습 데이터에 다량 추가함으로써 성능이 개선되지 않거나 오히려 악화시키는 경우도 발생 가능합니다. 그래서 저희는 태깅을 하지 않은 데이터로 학습 예제를 생성할 때, 각 예제의 위험성을 추정하여 학습에 반영함으로써 보다 안전하게 대량의 태깅 되지 않은 데이터를 랭킹 모델 학습에 사용할 수 있었습니다.
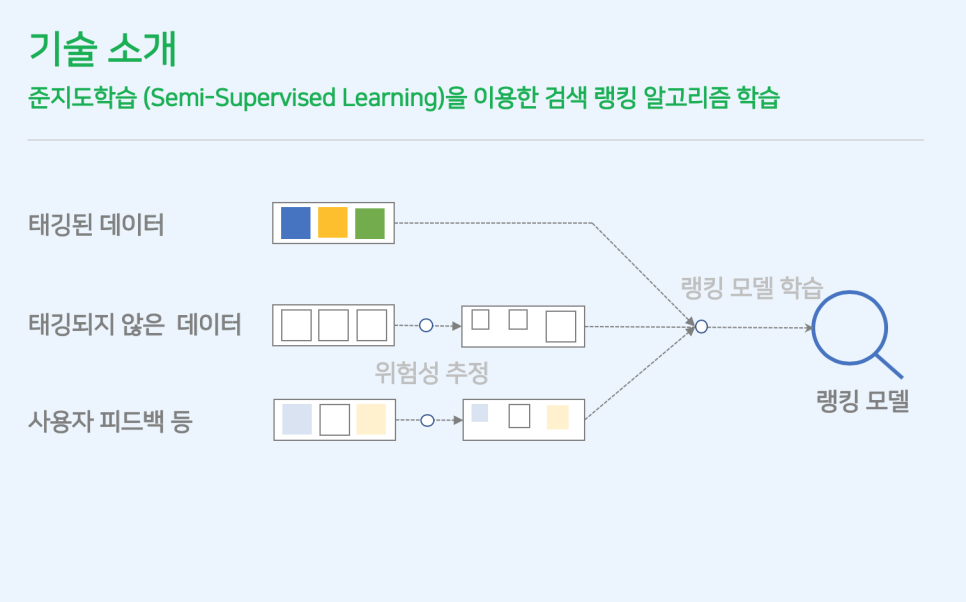
지난 10월 31일에 출시된 새로운 네이버 웹사이트 랭킹 모델은 이 방법을 이용하여 검색 품질을 향상시켰습니다. 이 접근법은 2019년 네이버 AI 콜로키움에서 Naver Search의 송영인 박사가 “Learning to Rank with Partially Labelled Training Set”란 제목으로 소개한 바 있습니다. 한정된 양의 태깅 된 데이터뿐만 아니라 대량의 태깅 되지 않은 데이터도 학습에 활용한 덕분에 더 정확한 랭킹 모델을 학습할 수 있었고, 이는 네이버 검색 품질 평가 가이드라인에 더 부합하는 결과를 내주는 랭킹 모델이 서비스에 적용됐다는 의미입니다.
다양한 AI 기술이 적용된 네이버 웹사이트 검색
랭킹 모델뿐 아니라, 검색 사용자의 정보 접근성과 만족도를 높이기 위한 AI 기술이 네이버 웹사이트 검색에 계속 추가되고 있습니다.




![[인사이트] 뷰티 실무자 100명이 같은 고민을 하고 있었다고?](https://cdn.ibos.kr/design/upload_file/BD74667/THUMBNAIL_300_200_7e6579acb58c54e8fcfeaecbd98b599a_51154_1.png)




















새댓글
전체보기