
서드 파티 쿠키의 제한,
리타게팅 광고는 사라질까?
2023년부터 구글 크롬이 제공해온 제 3자 쿠키(Third Party Cookie) 사용이 제한됩니다. 이번 이슈로 가장 큰 타격이 예상되는 곳은 애드테크 산업군입니다.
지금까지는 DMP에서 쿠키를 수집, 분석하여 DSP에게 분석된 고객 행동 데이터를 전달하였습니다. DSP는 전달받은 고객 행동 데이터를 기반으로 광고주가 효율이 좋은 매체의 인벤토리에 입찰할 수 있도록 돕는 역할을 해왔습니다. 이런 과정을 거쳐 웹브라우저 사용자는 방금 쇼핑하던 상품을 인터넷 뉴스 배너 광고에서 볼 수 있었습니다.
*더욱 자세한 디지털 광고 생태계 이야기가 궁금하다면?
'구글 크롬이 서드 파티 쿠키를 제한하면 생기는 일' 콘텐츠 보러 가기 (클릭)
하지만 서드 파티 쿠키 지원 중단이 예고되면서, 2023년부터는 애드테크 기업에서 해왔던 리타게팅 광고를 진행하기 어려워집니다. 이런 상황의 대안으로 언급되는 방법 중 하나가 바로 '핑거프린트(Browser Fingerprint) 기법'입니다.
이번 콘텐츠에서는 다가오는 서드 파티 쿠키 제한에 대비하는 대안책인 핑거프린트의 방법론부터 기대효과까지 알아보도록 하겠습니다.
서드 파티 쿠키가 없어도 괜찮아요.
새로운 대안책, 핑거프린트
지금까지는 서드 파티 쿠키를 수집하여 고객 행동 데이터를 분석했습니다. 하지만 점차 활용이 어려워지면서 '핑거프린트' 기술이 다시금 주목받고 있습니다. 핑거프린트란 쿠키를 이용하지 않고, 사용자의 웹브라우저 데이터를 이용하여 식별하는 기술입니다.
먼저, 핑거프린트 기법으로 사용자를 식별하려면 웹브라우저 내의 사용자 정보가 필요합니다. 사용자의 특징을 유추할 수 있는 수집 가능한 정보는 약 60가지이며, 대표적인 정보는 아래와 같습니다.
- 디바이스 정보 (맥북, 삼성, 아이폰, ... / CPU, memory, graphic, ...)
- 설정 언어 (한국어, 영어, 일본어, ...)
- audio (음향 설정 수치)
- viewport (사용자가 설정해두는 브라우저 창의 크기, ex: 1920*1080)
- 확장 프로그램 설치 개수
- 기타 등등의 사용자 설정 값 약 60여 개
하지만 수집된 모든 정보를 핑거프린트에 활용하는 것은 아닙니다. 변동성이 높은 데이터는 제외하여 수집된 데이터의 정확성을 높입니다.
수집된 사용자 데이터는
어떻게 활용할까요?
핑거프린트 기법은 아래 두 가지 방법론으로 보다 정확하게 사용자를 식별합니다.
(1) LSH(Locality sensitive hash) 알고리즘
(2) 분류 알고리즘 - KNN 알고리즘
(3) 분류 알고리즘 - Naive Bayes 알고리즘
먼저, LSH(Locality sensitive hash) 알고리즘부터 알아볼까요?
(1) LSH(Locality sensitive hash) 알고리즘
- LSH(Locality sensitive hash)란?
LSH는 해시 함수(Hash Function)를 이용하여 비교 대상과 속성 값의 유사도를 측정하는 데에 쓰이는 알고리즘입니다. 여기서 해시 함수는 임의의 길이를 가진 문자를 고정된 길이의 해시(Hash)로 바꿔주는 역할을 하며, 이러한 해시 함수를 적용하여 나온 고정된 길이의 값을 해시값(Hash value)라고 합니다.
이때 나온 고정된 길이의 해시값은 '단방향 암호화' 방식으로,이미 암호화된 값은 원래 어떤 문장이었는지 해독할 수 없습니다.
다시 말해, [CRM 마케팅 자동화 솔루션 빅인(bigin) —> 121 AbCDefgH34]라고 암호화됐다면
[121 AbCDefgH34 —> CRM 마케팅 자동화 솔루션 빅인(bigin)] 임을 확인할 수 없다는 의미입니다.
이러한 특징 때문에 해시값은 데이터의 보안 문제에서 비교적 자유롭습니다.
지금까지 LSH(Locality sensitive hash)의 개념에 대해 알아보았으니,
본격적으로 LSH(Locality sensitive hash)가 유사도를 측정하는 방법을 살펴볼까요?
LSH 알고리즘은 간단하게 3단계에 걸쳐 유사성을 확인합니다.
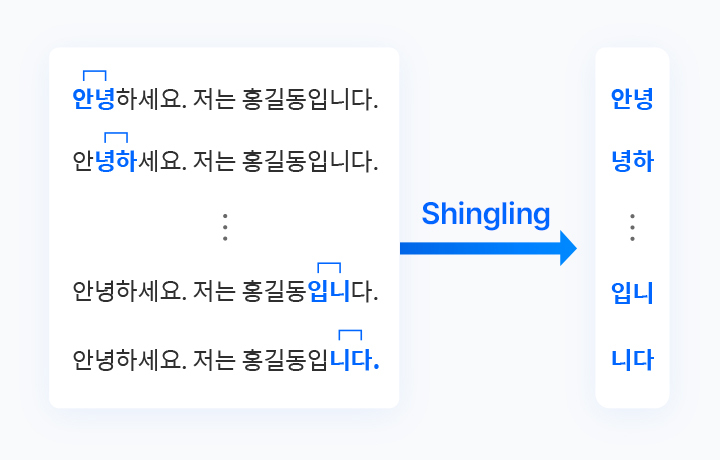
[LSH 알고리즘 1단계] 특정 문자를 N개의 문자열로 쪼개는 Shingling 작업
예를 들어 [그림 1]처럼, '안녕하세요. 저는 홍길동입니다.'라는 임의의 길이를 가진 문장이 있다고 가정해보겠습니다. 이때 세팅값을 2로 설정했다면, 앞의 문장은 '안녕/녕하/하세/.../입니/니다/.'로 두 글자씩 쪼개어집니다. 같은 방식으로 세팅값을 3으로 설정한다면 어떻게 될까요? 위의 문장은 '안녕하/녕하세/.../'로 나누어지겠지요.
이렇게 세팅한 값에 따라 문자를 쪼갠 후 2단계로 넘어갑니다.
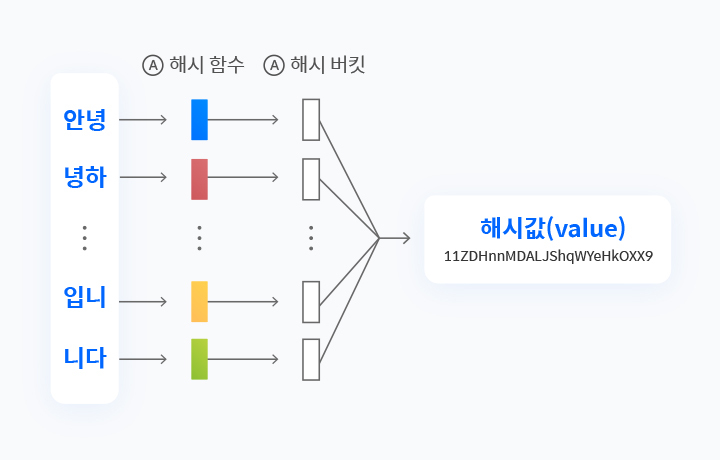
[LSH 알고리즘 2단계] 나누어진 문자를 암호화하는 Hash Shingling 작업
문자를 암호화하기 전, 문자를 해시로 변환하는 과정이 필요합니다. 이때 문자는 해시 함수를 이용해 해시로 변환됩니다. 이후 변환된 해시를 버킷에 저장하여 고정된 길이의 암호를 만들어냅니다.
이때 생성된 암호가 바로 해시 코드(Hash code), 해시섬(Hash sum), 체크섬(Check sum)으로도 불리는 해시값(Hash value)입니다.
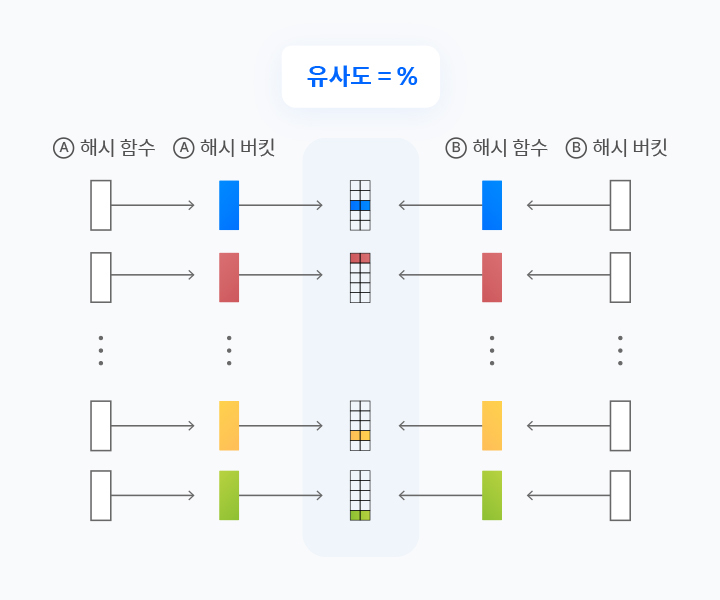
[LSH 알고리즘 3단계] 해시값(Hash value)을 다시 해시로 변환하여 유사도를 확인
마지막 3단계에서는 2단계의 프로세스를 반대로 진행하여 유사도를 확인합니다.
즉, [문자 쪼개기 → 해시 함수를 이용해 해시화 → 해시를 버킷에 저장 → 해시값으로 암호화] 했던 프로세스를 [암호화된 해시값 → 버킷에 저장 → 해시로 변환 → 다른 데이터와 유사도 확인]으로 다시 같은 과정을 반복하는 것입니다.
여기서 암호화되었던 해시값은 함수로 다시 변환해도 원래 어떤 문자였는지 해독할 수 없습니다. 때문에 처음 문자가 아닌, 변환된 해시를 매치하여 유사도를 측정합니다. 이렇게 나온 결괏값으로 유사도의 기준을 정립할 수 있습니다.
하지만 LSH 알고리즘은 정확도가 높지 않다는 문제점이 있습니다. 때문에 이런 문제를 해결하기 위하여 두 가지의 그룹 분류 알고리즘을 활용해야 합니다.
그룹 분류 알고리즘은 'KNN', "Naive Bayes', 두 가지를 이용합니다.
(2) KNN(K-Nearest-Neighbor)
- KNN(K-Nearest-Neighbor)이란?
KNN이란 앞선 해시값들을 일정 기준([그림 3]의 x, y축)에 따라 나열한 뒤, K라는 거리를 기준으로 데이터를 군집화시켜 어떤 그룹에 속하는지 분류하는 알고리즘입니다. 다시 말해, K라는 거리를 기준으로 새로운 속성 값과 주변 속성 값을 비교하여 더 많은 속성 값에 포함되는 그룹으로 분류하는 방식입니다.
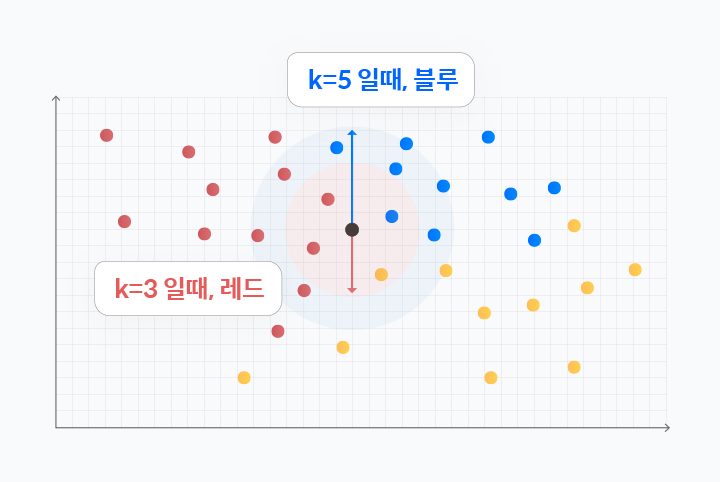
[그림 4]을 활용하여 좀 더 쉽게 KNN 알고리즘을 설명해보도록 하겠습니다.
[그림 4]의 그래프를 보면 가운데 '블랙'이라는 새로운 속성 값이 위치하고 있습니다.
KNN으로 분류하면 블랙은 어떤 그룹으로 분류될까요? 블랙을 중심으로 K(=거리)가 3일 때, 범위 안에는 레드 2개, 블루 1개, 옐로 1개의 속성 값이 있습니다. 이때 블랙은 레드 그룹으로 분류됩니다. 하지만 K(=거리)가 5인 경우는 어떨까요? 범위 안에 레드 5개, 블루 6개, 마지막으로 옐로는 1.5개의 속성 값이 있어, 블랙은 블루 그룹으로 분류됩니다.
이렇게 KNN은 어떤 새로운 속성 값이 주어졌을 때, 거리를 기준으로 군집화합니다. 때문에 거리 값을 어떻게 설정하느냐에 따라 결괏값이 달라질 수 있습니다.
(3) Naive Bayes Naive Bayes
- Naive Bayes란?
Naive Bayes란 속성 값을 확률적으로 예측하고 분류하는 알고리즘입니다. KNN에서 다르게 분류된 속성(ex. 블랙, 그린)일지라도 Naive Bayes에서는 그룹에 속할 확률을 분석하기 때문에 같은 그룹으로 분류될 수 있습니다.
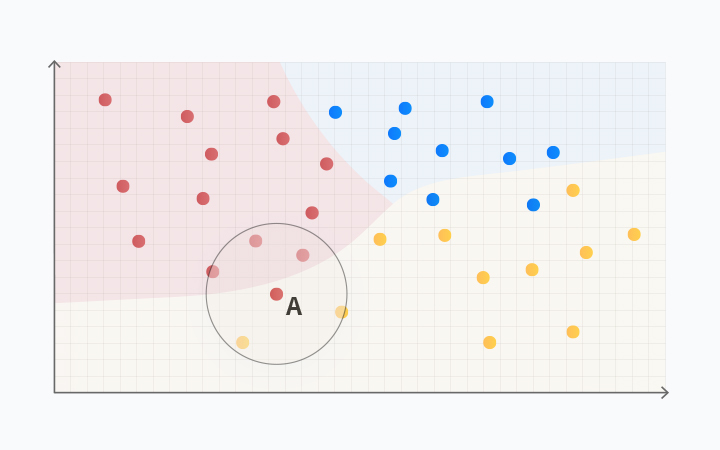
분명 다르게 분류되었던 속성 값이 어떻게 같은 그룹으로 분류될 수 있을까요?
먼저, Naive Bayes 공식을 활용하여 사전 확률을 구합니다. 이후 개별 특성들이 나타날 확률(=레드, 블루, 그린이 가진 특성이 나타날 확률)을 사전 확률과 곱합니다. 이때 나온 결괏값인 확률을 기준으로 그룹을 나누는 방식이 Naive Bayes 알고리즘입니다.
이렇게 Naive Bayes 알고리즘으로 그룹화한다면 [그림 5]처럼 속성 값을 분류할 수 있습니다.
[그림 5]의 KNN 알고리즘에 따르면 K(=거리)가 5일 때, 속성 값 A는 레드 그룹으로 분류되었습니다. 거리 내에는 레드의 속성 값이 더 많기 때문입니다. 하지만 데이터가 가진 속성들에 Naive Bayes 알고리즘을 적용해 보았더니, A는 확률적으로 옐로 그룹에 더 가까운 속성 값을 가지고 있었습니다.
확률에 따라 그룹화하는 알고리즘인 Naive Bayes는 예측을 위한 추정 확률을 쉽게 얻을 수 있다는 장점을 가지고 있어 일반적으로 스팸 메일을 분류하는 데에 사용됩니다.
예를 들어 스팸인지 아닌지 구분할 수 있는 속성 값을 먼저 정하고(ex. 할인, 대박, 감사), 각 데이터 별로 해당 단어가 내용에 포함이 되어 있으면 1(포함), 포함되어 있지 않으면 0(미포함)으로 가공합니다. 이후 가공된 데이터를 Navie Bayes 알고리즘으로 분류하게 되면 속성이 포함된 확률에 따라 스팸 메일 여부를 구분할 수 있습니다.
핑거프린트 기법으로도 할 수 있어요.
사용자 식별부터 개인화 마케팅까지
핑거프린트 기법은 지금까지 살펴본 두 가지 알고리즘을 활용해 높은 정확도로 사용자를 구분합니다. 살펴본 방법론을 기반으로 핑거프린트 프로세스를 간단하게 요약해보자면 아래와 같습니다.
- 웹브라우저 내에서 사용자를 식별할 수 있는 정보를 수집해 해시값을 얻는다.
- 웹브라우저의 raw data를 KNN 또는 Naive Bayes로 분류하고, 새로운 사용자의 정보도 같은 알고리즘으로 분류한다.
- LSH 알고리즘을 활용하여 분류된 새로운 사용자의 해시값과 raw data의 해시값의 유사도를 측정한다.
- 측정한 유사도에 따라 같은 사람인지, 다른 사람인지 판단한다. (유사도가 90% 이상이면 같은 사람으로 판단함)
이러한 핑거프린트 기법을 활용하면 어떤 성과를 기대할 수 있을까요?
가장 중요한 핵심 두 가지를 정리해 보았습니다.
[사용자를 보다 정확하게 식별하고, 그룹화할 수 있어요.]
핑거프린트는 쿠키가 아닌 웹브라우저 정보에 기반하여 사용자의 특징을 파악합니다. 때문에 쿠키가 제한되더라도 정보 데이터 간의 유사도를 분석하여 사용자를 식별할 수 있습니다.
또한 KNN과 Naive Bayes, 두 가지 분류 알고리즘을 활용해 그룹화하기 때문에 그룹 분류의 정확성을 높일 수 있습니다.
[유사한 사용자에게 똑같은 마케팅 액션을 수행할 수 있어요.]
사용자 정보를 분석하여 그룹화하고 유사도를 확인하는 핑거프린트 기법을 활용한다면, 유사한 사용자에게 적절한 마케팅 액션을 수행할 수 있습니다.
예를 들어, 뷰티 제품을 판매하는 온라인 쇼핑몰에는 X라는 새로운 사용자가 유입되었습니다.
먼저, 웹브라우저 내 X의 정보를 수집하여 KNN, Naive Bayes 알고리즘으로 분류합니다. 이후 그룹으로 분류된 데이터는 LSH 알고리즘으로 기존 사용자였던 A, B, C의 데이터와 비교합니다. (핑거프린트 과정)
이때 A와의 유사도는 70%, B와의 유사도는 80%, C와의 유사도는 90%였다면, X는 C와 유사한 것으로 판단이 가능합니다. 같은 방법으로 서드 파티 데이터로 해왔던 리타게팅 광고도 쿠키 없이 가능합니다.
그렇다면 기존에 C에게 노출시켰던 캠페인을 X에게도 똑같이 노출시킬 수 있습니다.
지금까지 핑거프린트 기법의 전반적인 개념과 방법론부터 기대 효과까지 살펴보았습니다.
서드 파티 쿠키의 제한으로 디지털 업계에 위기가 찾아온 것은 사실입니다. 하지만 이제는 퍼스트 파티 데이터, 핑거프린트와 같은 새로운 대안책을 찾고, 이런 대안책 잘 활용하여 위기를 어떻게 극복할 것인지 고민하는 시간이 필요한 때입니다.
* 참고 콘텐츠
'다시 찾아온 퍼스트 파티 데이터의 시대' 콘텐츠 보러 가기 (클릭)
앞으로도 저희 빅인은 급변하는 디지털 시장에 발 빠르게 대비하며, 변화에 필요한 마케팅 인사이트와 전략을 지속적으로 공유할 예정이오니 꾸준한 관심으로 지켜봐 주시기 바랍니다.
>>변화에 필요한 마케팅 인사이트와 전략이 궁금하다면? 빅인에 문의하기
* 이번 콘텐츠는 빅인사이트 데이터 사이언티스트 전진형님이 작성해주신 기술 블로그를 바탕으로 편집한 내용입니다.


아직 등록된 댓글이 없습니다.
bigin님의 게시글에 첫번째 댓글을 남겨보세요.