

네이버 블로그로 좋은 웹문서를 만들기 위해서는 관점을 바꿔야하지 않을까 생각합니다.
지금까지 방법적인 부분으로 약간의 변화를 준다고 해도,
기존의 로직을 바탕으로 하는 방법이기에,
글 쓰는것도 힘들 것이고,
기존의 경쟁자들을 이기기 힘들 것입니다.
그렇다면,
어떠한 부분을 달리 생각해서 좋은 웹문서를 만들 수 있을까요??
검색엔진 | 검색 순위 원리에 대하여
좋은 웹문서와 신뢰 있는 웹사이트를 이해하기 위해서는 가장 먼저 검색엔진과 검색 순위 원리를 이해를 해야 합니다.
이러한 검색엔진과 검색 순위의 원리를 이해하기에는 너무나 많은 시간이 들어가기 때문에 간단하게 정리를 해보겠습니다.
우리는 웹문서 순위를 위해 1등의 페이지를 분석하고,
키워드 이미지 수를 분석하고,
글자수를 분석합니다.
분석하는 시점 자체가 검색에 나오는 문서들을 기준으로 하였기때문에 그렇습니다.

위에 방법으로 분석을 할 경우,
그 키워드로 들어온 사용자의 스타일을 분석할 수는 있습니다.
하지만 검색엔진 | 검색 순위가 어떤 방식으로
순위를 먹이는지는 알 수가 없습니다.
논리적으로 생각을 해보세요!!
저 글을 쓴 사람은 어떠한 원리로 검색엔진, 검색 순위에서
높은 점수를 먹고 상단에 들어갔을까요??
그리고 검색엔진은 왜 저 상단의 문서를 상단에 올렸을까요??
모든 검색엔진으로 운영을 하는 포털 기업의 수익 중 가장 큰 수익원은 광고 입니다.
이러한 광고는 사람들이 많이 찾을 수 있는 조건을 갖추어야 합니다.
그리고 그 조건이 갖춘 문서에 광고를 달면,
수익은 좋아집니다.
그렇다면 상단에 있는 문서들은 왜 상단에 올라갔을까요??
그리고
그 글을 약간 수정을 하여 글을 썼을 때,
나는 상단에 올라가지 못할까요??
" 많은 사람들은 유사 문서 때문이다, 아니면 SEO가 안되어 있다.
이미지가 잘못되었다. "
여러 이유를 이야기 할 것입니다.
우리가 이해 해야 하는 부분은 검색엔진이 왜 상단의 문서를
가장 잘 보이게 하는지를 파악 해야 합니다.

" 차이점을 모르시겠다고요??
간단하게 생각하세요.
우리는 검색엔진이 선택한 가장 좋은 웹문서의 조건을 모르고,
검색엔진이 선택한 가장 좋은 웹문서를 분석하고,
비슷하게 만들고 있는 것입니다."
이럴 경우 무엇이 문제냐!!!
다양한 웹문서 데이터들이 많아질 경우,
검색 순위의 조건들이 변화가 될 겁니다.
그래서 네이버의 경우 최근 상단 반영해주는 (2021년 하반기) 조건들이 과거와는 다른 형식을 보이게 됩니다.
검색엔진 뒤에 있는 색인서버를 통해 데이터를 수집하고,
이 데이터를 기반으로 순위를 만들게 됩니다.
한번씩 다 읽어봤을 문서입니다.
위에 내용을 관점을 바꾸어서,
해석을 해야합니다.
"그냥 문장으로 해석을 하지마시고,
데이터로 적용한다고 했을 때
어떻게 구현을 했을까를요~!!!"
시스템은 문장을 인간처럼 이해 못합니다.
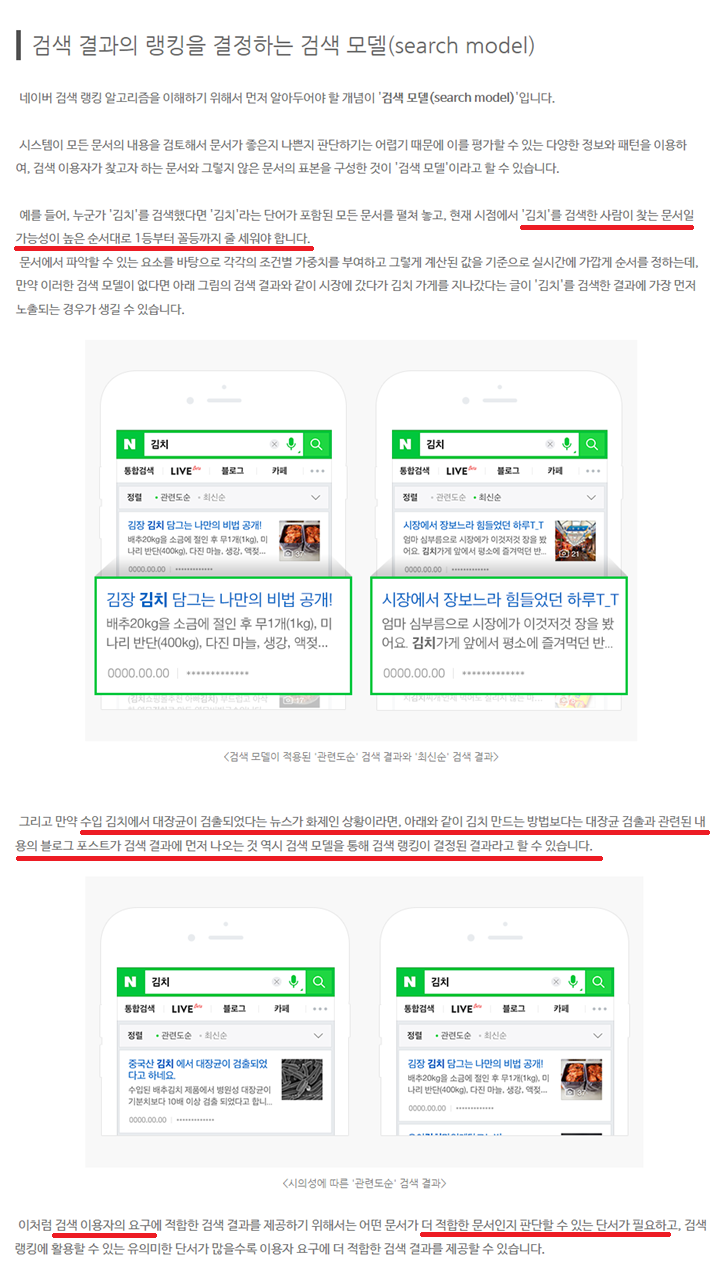
제일 상단에 내용을 보시면,
"김치를 검색한 사람이 찾는 문서일 가능성이 높은 순서대로 1등부터 꼴등까지 줄 세워야 합니다."
이 내용은,
웹문서를 1등부터 꼴등까지 줄을 세운다는 내용입니다.
등수를 정한다는 부분을 알려주는 것입니다.
그럼 어떠한 데이터로 등수를 정할까요?
C rank는 아직까지 네이버가
사용하는 알고리즘입니다.
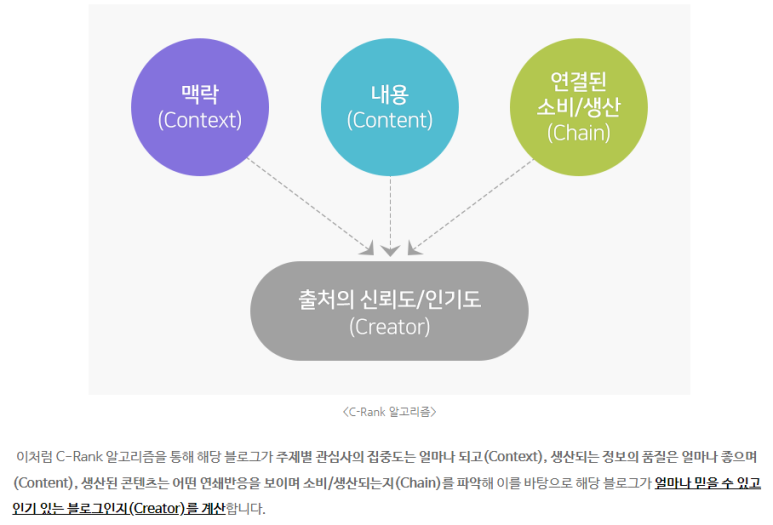
저 위에 내용을 데이터 변환이 어떻게 되는지를 파악해야합니다.
물론 과거의 자료이므로,
저 위에 내용 + @가 더 들어갔겠지만,
@는 Crank를 업데이트하지 않고,
DIA 알고리즘을 변화를 줄것이라고 생각합니다.
C rank관련하여 네이버는 친절하게 설명을 하였습니다.

여러분들은 " 네이버 라이브 검색 " 서비스라는것을 검색 해보셨나요?
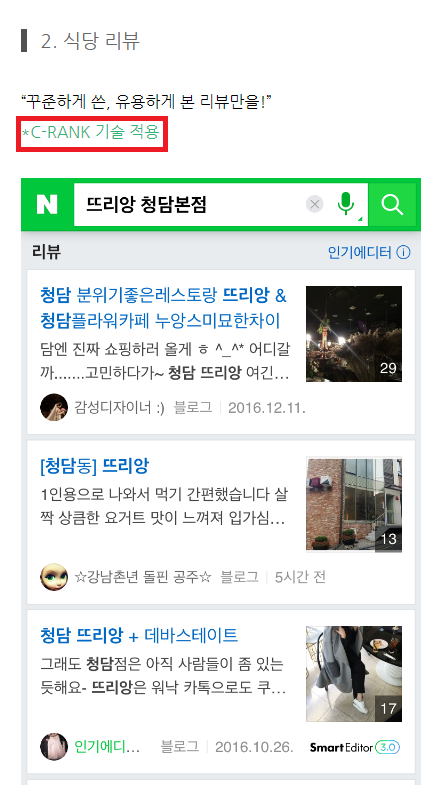

1. 해당 키워드로 문서 태그로 작성하거나 관련 주제에 꾸준한 글을 작성했는지 여부
2. 클릭외 좋아요 공유 댓글 구독 등의 수치를 활용해 문서의 신뢰도와 인기도 측정
* 활용한다는 거은 저 데이터를 기반으로 다른 데이터와 비교를 한다는 뜻으로 볼 수 있습니다. 저 데이터를 그대로 랭킹데이터에 넣는 다는것은 아니죠!!!
2017년에 이미 저런 방법적인 부분은 네이버가 알려줬습니다.
그래서 좋아요 이웃추가 품앗이가 나왔겠죠?
최근에는 이웃추가 품앗이 프로그램 돌리면,
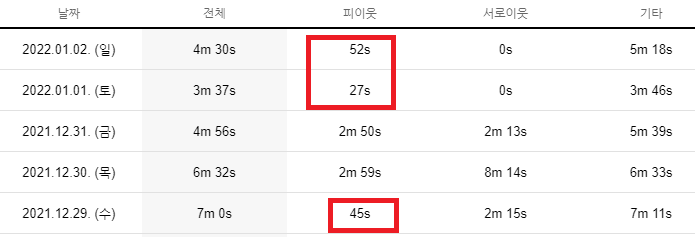
상대방 데이터를 이용하여,
체류율을 통해 확인이 가능합니다.
하물며,
좋아요를 누르고,
그냥 나가면,
글 조회수는 늘어나지도 않습니다.
저런 품앗이 프로그램은
서로에게 도움이 되지 않습니다.
관점을 바꾸어서 생각을 하시길 바랍니다
네이버는 Crank와 DIA 로직을 이용해서,
순위를 주고 있습니다.
그런데 저런 좋아요 댓글 의 수치를 활용해서 데이터를 뽑는 다는것은
다른 데이터와 비교해서 %로 비율을 만들어,
랭킹데이터를 만들 것입니다.
그래서 전에 쓴 연관성에 대한 부분을 인지하면서,
나에게 순위 영향을 주는 데이터가 어떤것인지 찾으시면서,
글을 작성해야합니다.
분명한 사실은 네이버 서비스 정책 문서에
관련 힌트들이 숨어있다는 것입니다.
단순 문장에 대한 내용들을데이터 적용법으로 해석하여,연관을 짓고,보시면 조금 더 좋은 웹문서 작성에 도움이 되실겁니다.

























새댓글
전체보기